Even Faster Gaussian Processes in STAN Using functions
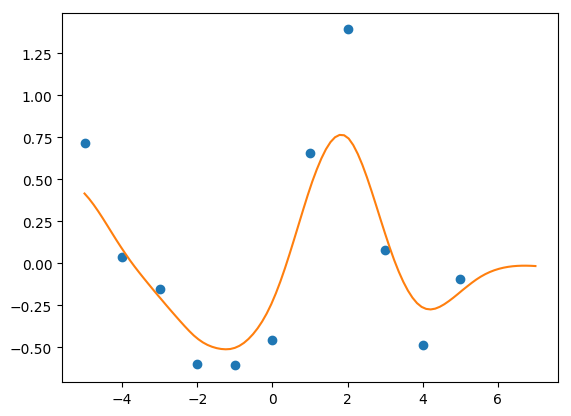
In my last post, I discussed how to get predictions from Gaussian Processes in STAN… Read More »Even Faster Gaussian Processes in STAN Using functions
In my last post, I discussed how to get predictions from Gaussian Processes in STAN… Read More »Even Faster Gaussian Processes in STAN Using functions