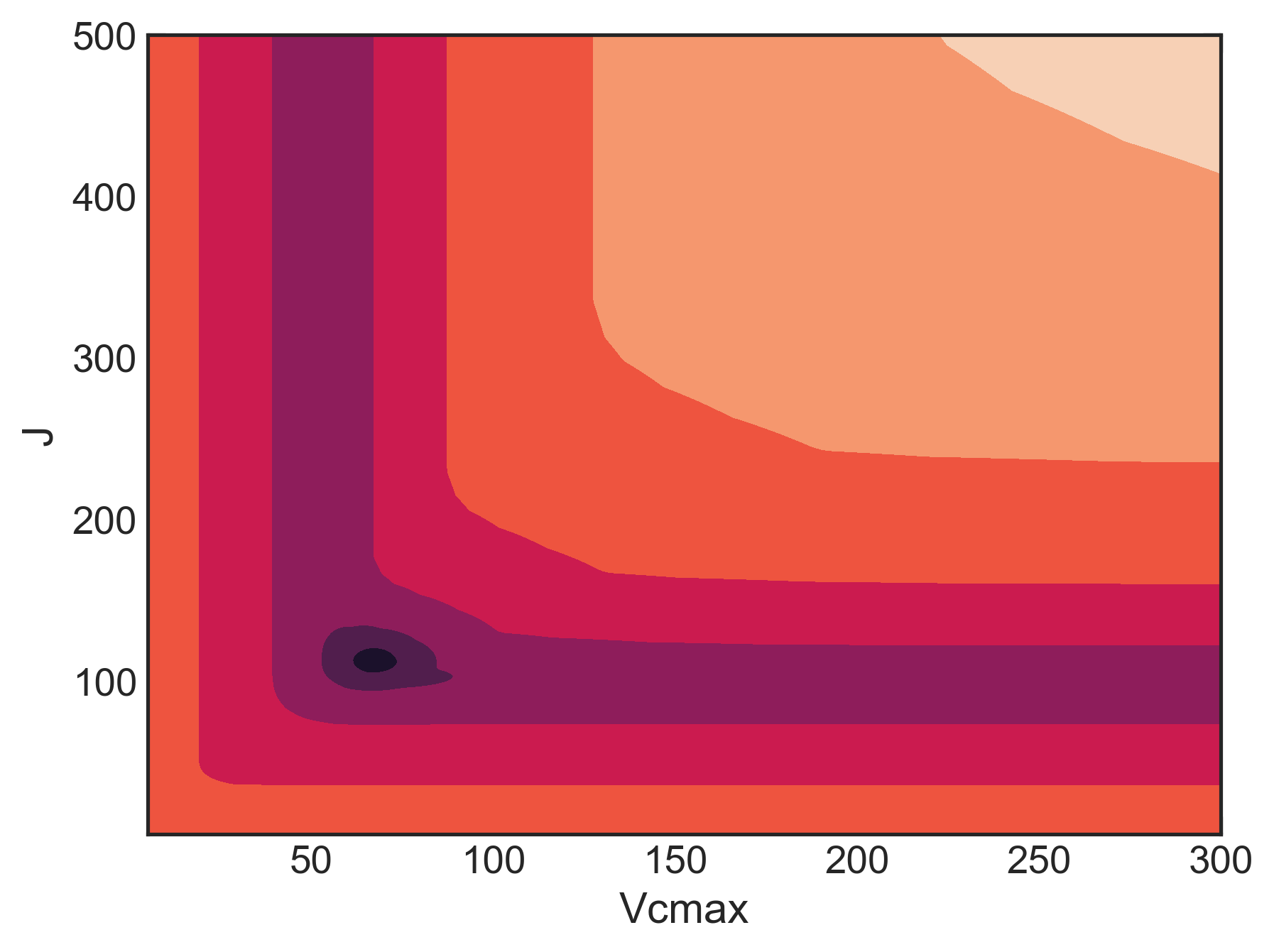
An Efficient Algorithm for Estimating A-Ci parameters
Foliar A/Ci curves, which relate carbon biochemistry to photosynthesis rates, provide an extraordinary amount of… Read More »An Efficient Algorithm for Estimating A-Ci parameters
Foliar A/Ci curves, which relate carbon biochemistry to photosynthesis rates, provide an extraordinary amount of… Read More »An Efficient Algorithm for Estimating A-Ci parameters
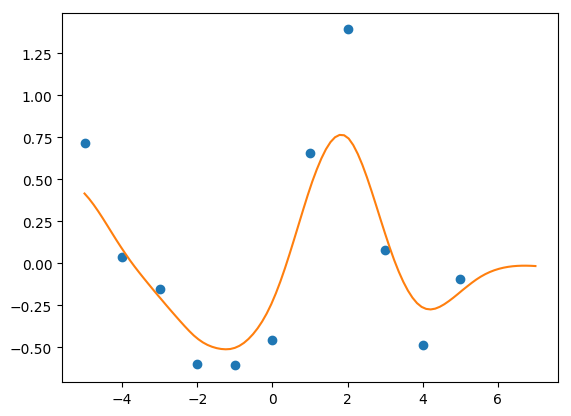
In my last post, I discussed how to get predictions from Gaussian Processes in STAN… Read More »Even Faster Gaussian Processes in STAN Using functions
As described in an earlier post, Gaussian process models are a fast, flexible tool for… Read More »Fast Gaussian Process Models in STAN
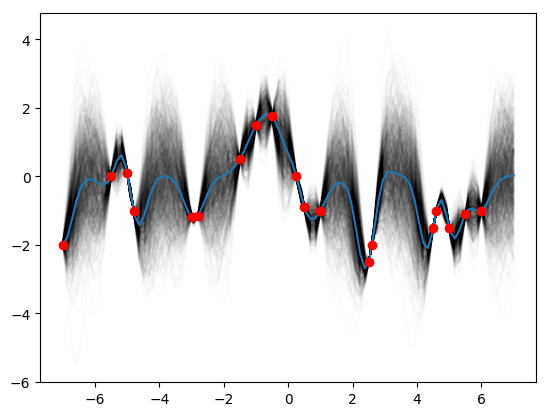
Gaussian Processes for Machine Learning by Rasmussen and Williams has become the quintessential book for learning… Read More »Gaussian Processes for Machine Learning in Python 1 Rasmussen and Williams – Chapter 2